< SRGAN 논문 리뷰 >
논문 주소: arxiv.org/abs/1609.04802
논문 요약 -->
Super Resolution에 GAN을 적용한 논문
기존 Super Resolution들은 MSE loss를 사용하여 복원을 하다보니 PSNR 수치는 높지만 다소 블러가 낀 결과를 내고 있음을 지적하였고 이를 해결하기 위하여 GAN을 적용한 논문이다.
시작하기에 앞서,
Image Super Resolution이란?
저해상도(Low Resolution) 이미지를 고해상도(Super Resolution) 이미지로 변환시키는 일을 의미한다.
Super Resolution은 크게, 하나의 이미지를 이용하는지, 여러 이미지를 이용하는지에 따라서
1) Single Image Super Resolution
2) Multi Image Super Resolution
위의 두가지로 나뉜다. 이 논문에서 사용하는 것은 Single Image Super Resolution이다.
1. Introduction
MSE(Mean Square Error) loss 와 같은 경우는 pixel wise average loss 이기 때문에 평균을 내어 지나치게 부드럽다. 즉 high texture detail 과 같은 지각적으로 관련있는 차이를 잡기에 제한적이다.

실험 결과에서는 PSNR (high-peak-signal-to-noise ratio, 성능지표이며 Distortion measure로 쓰임) 수치는 떨어졌지만 사람 눈에 보기엔 보다 정확해 보인다.
키워주고자 하는 배수가 커질수록 효과를 볼 수 있다. (논문에서는 4배수에 대해 실험을 수행)
그래서 이 논문에서 제안하는 것은 GAN을 이용하여 super resolution을 추정한다는 점과 VGG network의 high level feature map과 discriminator를 결합한 새로운 perceptual loss을 제안한다는 점이다.
여기서 Perceptual loss는 pre-trained 된 vgg를 사용하여 feature map 에서의 Euclidean 거리를 계산하는 방법이다.



논문에서 정의하고 있는 perceptual loss 이다.
여기에서는 생성된 Super Resolution 이미지에 적절한 특성들을 다루는 loss 요소들의 가중치를 합한 값이다. 우리는 perceptual loss를 이용하여 generator의 parameter를 최적화하는 것이 목표이다. 자세한 로스들은 2.2 perceptual loss funciton에서 다루어 보도록 한다.
2. Method
2.1. Adversarial network architecture

우리가 잘 알고 있는 GAN의 기본 공식이다.
Super Resolution과 Ground Truth 를 구별하도록 훈련된 Discriminator를 속이도록 Generator를 훈련시키는 것이다.
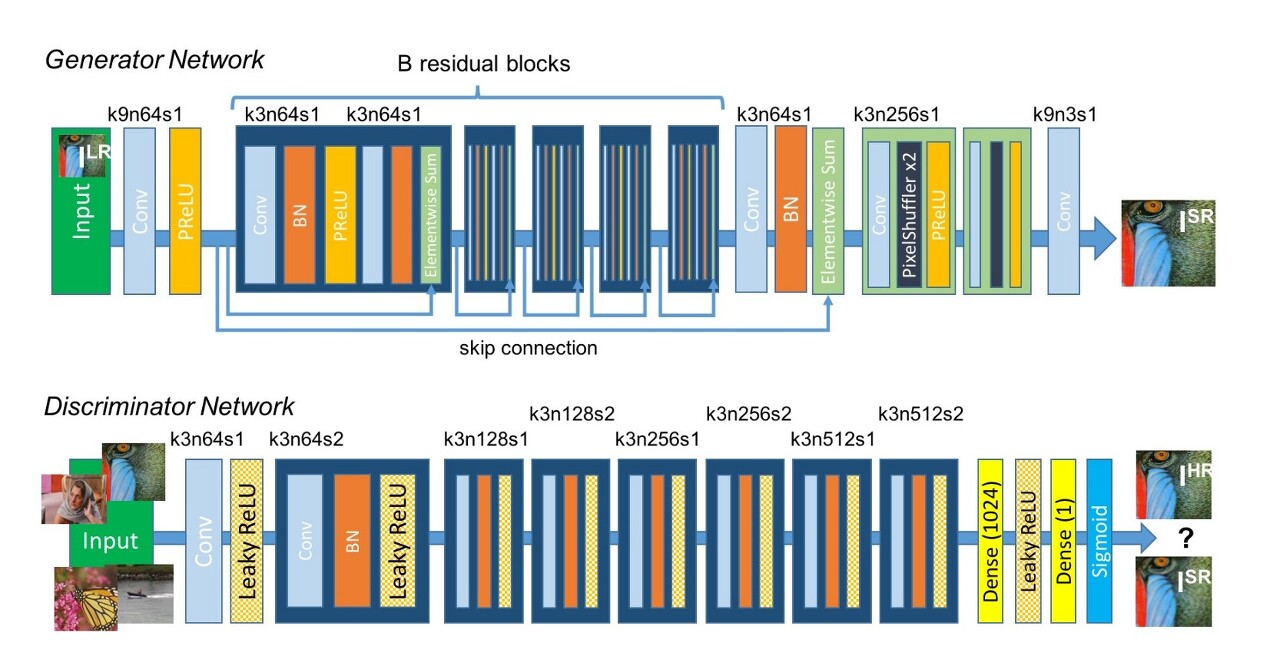
- 아주 deep한 Generator network의 핵심은 B residual blocks 에 있다.
- Super Resolution을 할 적에 pixel 수가 당연히 늘어날텐데 일반적으로 CNN에서 filter를 거치면 image의 dimention은 줄거나 동일(valid or same)하다. 이때 여기서 pixel 수를 늘리는 방법이 sub-pixel convolution algorithm이다.
여기서 sub-pixel convolution이란 최종 Low Resolution feature map을 High Resolution으로 upscale하기 위해 upscale필터를 학습하는 것이다.
2.2. Perceptual loss function
perceptual loss를 알기 위해서 아래의 그림을 보면 좀 더 이해를 하기 쉬울 것이다.

여기서 방식을 살펴보면, 원본 High Resolution 이미지를 Low Resolution으로 낮춘 후 High Resolution 이미지로 복구시키는 방식이다.
이를 통해 새로운 이미지가 들어왔을 때 기존의 학습된 모델을 바탕으로 Super Resolution 이미지 생성할 수 있다.
Perceptual Loss의 구성

즉,
1) Content loss: Ground Truth와 생성된 이미지의 VGG로부터 추출된 feature map 차이
2) Adversarial loss: D를 속임으로서 실제 이미지와 비슷하도록 Generator를 학습한 것으로부터의 차이
1) Content loss
MSE의 loss는 아래처럼 계산된다.

높은 PSNR를 얻을 지라도, 실제로 사람이 눈으로 판별했을 때는 그다지 좋은 성과를 내지 못한다.
따라서 pixel wise loss 대신에 VGG loss를 사용한다.

- 여기서 ϕij는 vgg19애서 i 번째 maxpooling layer를 거치기 전인 j 번째 conv layer에서 얻은 feature map
- e GθG (I LR)(생성된 이미지의 특징 대푯값) 과 I HR(ground truth) 사이의 유클리드 거리 측정
2) Adversarial loss
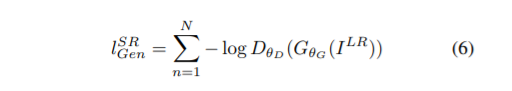
기존의 GAN의 Discriminator 최적화와 같다. Generator에 대한 loss
실제 코드에서는 Generator로 학습한 모델을 통해 추출한 Super Resolution 이미지와 Ground Truth 간의 MSE를 통해 계산한다.
위 adversarial loss 수식을 보았을 때 우리가 원래 알던 모양과 약간 다르다는 것을 알 수 있다.
알던 모양 : [1-logx]
왜 모양이 변형되었나? -> Gradient 때문.
1-log(x)를 이용하면 초반의 기울기의 변화가 매우 작아 학습이 잘 이루어지지 않는다고 한다.
하지만 -log(x)를 이용하면 학습 초반의 기울기가 매우 커진다. 따라서 gradient 의 begavior 가 훨씬 좋아진다.
3. Experiments
3.4. Investigation of content loss

위의 결과는 SRResNet과 SRGAN에서 loss 에 따른 성능을 비교한 것이다.
4. Discussion and Future Network

데이터셋에 따라서 bicubic, SRResNet, SRGAN 을 비교한 사진이다.

Reference
- https://awesomeopensource.com/project/deepak112/Keras-SRGAN
'논문리뷰' 카테고리의 다른 글
| Pix2pix 논문리뷰 | Image-to-Image Translation with Conditional Adversarial Networks (0) | 2020.06.05 |
|---|

댓글